 Text splitting concepts
Text splitting concepts
Rules text files
Wincaps Q4 is supplied with a set of sample text (.txt) files containing rules for the way text should be split under certain conditions. Those conditions are specified in the files.
You can use the sample files provided with the installer to implement basic automatic text splitting for the English language. To configure text splitting for other languages you should create another set of .txt files as appropriate and import them into the DataStore with the corresponding language is active.
A decision to split text can be based on linguistic data associated with grammar or parts of speech, punctuation or the amount of text present. For example, a phrase such as "Man of War" can be specified to be kept together. Splits can be specified to occur towards the middle of a second line of text, potentially reducing the likelihood of an orphaned word following the split. Splits before conjunctions can be favoured and splits following prepositions can be discouraged.
There are four categories of text-splitting rules files, namely:
-
Word-type files : these specify the grammatical classes of key words
-
Boundary weights files : these specify the splitting weights used by different word classes
-
Punctuation weights files : these specify the weightings before and after punctuation
Word-type files
These files each identify a grammatical class of words or phrases that should not be split. The file name conforms to the format TYPEc.txt, where c can be A, B, C, D...Y. Note that Z is not permitted. Thus, a file named TYPEA.txt can be created to contain common multi-word phrases that should not be split. The content of the file is a list and may contain entries as follows:
;TYPEA - Multi-word phrases
that he
that she
that it
Similarly, a TYPEB.txt file can be created to contain articles, as :
;TYPEB - Articles
a
an
the
Additional types can be set up to specify conjunctions, prepositions, compound proper names (Houses of Parliament, Prime Minister etc.).
Boundary weights file
The Boundary weights file is a single file named BOUNDING.txt. This file contains a list of three values for each type file that is defined and a system-related TYPEZ file which is reserved for words that only contain digits.
The BOUNDING file contains weighting rules that are defined by values in the range 0 - 9. The higher the weighting at a given inter-word space, the more likely the subtitle is to be split at that point. Each word type is assigned three weights:
-
before the word : the weight contributed by that word to the space before it
-
compound : the weight attributed to the spaces within a compound phrase
-
after the word : the weight contributed by that word to the space after it
Thus, in the case of our TYPEB example (shown above), weightings can be specified to minimise the likelihood of a split occurring after an article and increase the probability of a split being placed before it. A weighting rule might then be defined as 8,0,2 - where 8 is the weight for "before the word", 0 is the weight for compound (no rule required as the article is not part of a compound phrase) and 2 is the weight assigned for "after the word". This would appear in a BOUNDING.txt file as follows:
;Boundary Weights
B 8,0,2
The neutral weight is 4, and a word not appearing in any file (or appearing in more than one and not being resolved) will be given the neutral weighting. Spaces which have a weighting average below 4 are less likely to be selected as the point at which the subtitle will be split.
Punctuation weights file
The PUNCTWGT.txt file contains weightings for punctuation characters. Each line in this file has the format:
-
ASCII code : is the ASCII character code of the punctuation character
-
before : is the weight when it appears as leading punctuation
-
after : is the weight when it appears as trailing punctuation
The value -1 for either a "before" or "after" weight means "not applicable" and forces the punctuation to be either trailing or leading (not both) when the text is scrutinised by the application.
Note that the full-stop, question mark and exclamation mark do not need to be defined with any weights as these have already been pre-defined within the application to represent the end of a sentence, that terminates any subtitle.
The following image exemplifies the use of text-splitting rules related to punctuation weights:
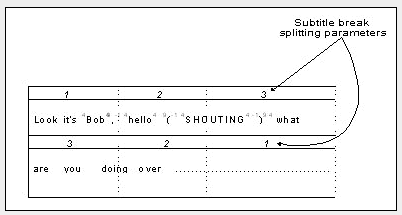
The subtitle text is too long for a two line subtitle. The comma, open bracket and close bracket all have an influence on where the subtitle should be split. In this case the highest weighting value in the text occurred after the close bracket punctuation (when also multiplying the average weight by the subtitle split parameters). So the split occurs after the closing bracket in this example.
Abbreviations File
This is used to avoid splits after abbreviations, for example Mr Johnson could split after the Mr putting Johnson on the next line. If Mr is in the abbreviations file, the split will keep Mr Johnson together. The file can also be used for abbreviations or words that have a full stop as part of the word or abbreviation that is not a sentence end full stop. Therefore if the auto-capitalise option is ticked, then words or abbreviations in the Abbreviations file will be exempt from this setting.