 Text splitting reference
Text splitting reference
Subtitle splitting geometry
When deciding where best to split a subtitle, it is not sufficient only to work on the basis of grammatical weights. The geometry needs to be considered, too. In a two-line buffer, for example, it is best to favour a split somewhere in the middle of the second line, rather than to choose the best word weight from the entire buffer. This avoids splitting off short fragments at either end and keeps the flow of text even. Suitable geometric weights therefore need to be specified in order to make sure a subtitle will be split at the optimum place.
These parameters are entered in the Splitting dialog, comprising a series of comma-separated numbers in the range 1 - 10 for the curve you wish to develop.
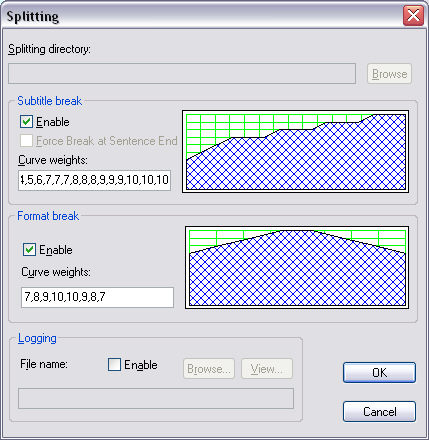
More points than those illustrated (above) can be entered to create a smoother curve if required. When analysing the subtitle, the curve will multiply the weight for the available text.
In Wincaps Q4 the splitting files (e.g. the TYPE and WEIGHT files) are held in the DataStore, hence the splitting directory path name is not used.
In the Subtitle break and Format break sections, the enable check boxes are used to activate the subtitle splitting weightings parameters. The subtitle break applies to the weighting of the boundary values within the two-line buffer. The format break applies to the weighting of the values within the split-off text.
A curve pattern specified by 1,2,2,3,3,3,2,2,1 influences the splitting decision so that the subtitle split is more likely to occur somewhere near the middle of the subtitle rather than near to the beginning. This also helps minimise the situation where using the weightings specified in the weights file only may cause an undesirable split to be made after the first word of a 2-line subtitle.
Calculating weightings
To work out final weightings after/before each word within a sentence, the system averages the "after" weight of the previous word and the "before" weight of the next word. It then multiplies this figure by a parameter specified by the user in the Curve weights section of the dialog.
The curve weights in the subtitle break effectively split the subtitle buffer into a number of zones - as many zones as weight values, each zone having the corresponding weight. The average inter-word weight is then multiplied by the zone weight to give a resultant weight.
For example, consider the text "The mercenaries insisted Mr. Cook had issued a licence allowing UN Sanctions to be...".
This sentence is too long to fit in the subtitle and Wincaps Q4 must decide where to split the text based on defined rules. Assume the Subtitle break curve weights have been set up to be 1,2,3,3,2,1; words "the" and "a" are specified in TYPEB.txt "articles" file (See Text splitting concepts) and this file has a Type weighting of 9,0,0, and that all other words have neutral weightings as they are not specified in any of the other type files.
Now, Wincaps Q4 uses the final weighting values on which to base its decision for where to split the subtitle.
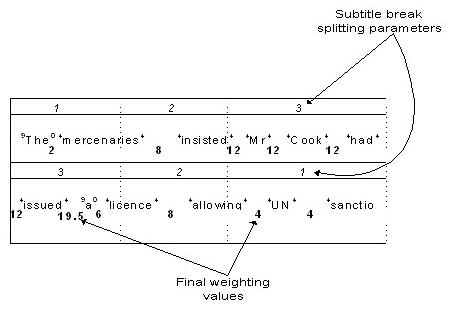
In the above diagram, the highest weighting occurs between the words "issued" & "a". The way the weighting is calculated is as follows :
-
add trailing weight of previous word to leading weight of next word 4 + 9 = 13
-
find average of weights 13/2 = 6.5
-
multiply the average weight by the parameter for that section of the subtitle 6.5 x 3 = 19.5
The subtitle is split after the word "issued", giving a reasonable split based on grammar and geometry.
Format break
The format break tells Q4 how to format the subtitle after the split location has been determined by the subtitle break. If the format break is not enabled, the system will not re-format the subtitle, but simply split it according to the subtitle break weightings and rules.
In summary, the two curves (subtitle and format) modify the syntactic weights as specified in the weights and type files, before the subtitle-break and line-break decisions are made. By an appropriate choice of grammar files and curves, sensitive context-dependent splitting decisions can be made, giving good results in the majority of cases.